普通模式:
普通模式正常的生产者和消费者模式,又分为简单模式Hello World和工作队列模式Work Queue
1 简单模式Hello World
生产者实现思路:
创建连接工厂ConnectionFactory,设置服务地址127.0.0.1,端口号5672,设置用户名、密码、virtual host,从连接工厂中获取连接connection,使用连接创建通道channel,使用通道channel创建队列queue,使用通道channel向队列中发送消息,关闭通道和连接。
消费者实现思路
创建连接工厂ConnectionFactory,设置服务地址127.0.0.1,端口号5672,设置用户名、密码、virtual host,从连接工厂中获取连接connection,使用连接创建通道channel,使用通道channel创建队列queue, 创建消费者并监听队列,从队列中读取消息。
2 工作队列模式Work Queue
功能:一个生产者,多个消费者,每个消费者获取到的消息唯一,多个消费者只有一个队列
任务队列:避免立即做一个资源密集型任务,必须等待它完成,而是把这个任务安排到稍后再做。我们将任务封装为消息并将其发送给队列。后台运行的工作进程将弹出任务并最终执行作业。当有多个worker同时运行时,任务将在它们之间共享。
生产者实现思路:
创建连接工厂ConnectionFactory,设置服务地址127.0.0.1,端口号5672,设置用户名、密码、virtual host,从连接工厂中获取连接connection,使用连接创建通道channel,使用通道channel创建队列queue,使用通道channel向队列中发送消息,2条消息之间间隔一定时间,关闭通道和连接。
消费者实现思路:
创建连接工厂ConnectionFactory,设置服务地址127.0.0.1,端口号5672,设置用户名、密码、virtual host,从连接工厂中获取连接connection,使用连接创建通道channel,使用通道channel创建队列queue,创建消费者C1并监听队列,获取消息并暂停10ms,另外一个消费者C2暂停1000ms,由于消费者C1消费速度快,所以C1可以执行更多的任务。
producer生产者:
# !/usr/bin/env python
import pika
credentials = pika.PlainCredentials('admin','123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.56.19',5672,'/',credentials))
channel = connection.channel()
# 声明queue
channel.queue_declare(queue='balance')
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='balance',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
consumer消费者:
# _*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
credentials = pika.PlainCredentials('admin','123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.56.19',5672,'/',credentials))
channel = connection.channel()
# You may ask why we declare the queue again ‒ we have already declared it in our previous code.
# We could avoid that if we were sure that the queue already exists. For example if send.py program
# was run before. But we're not yet sure which program to run first. In such cases it's a good
# practice to repeat declaring the queue in both programs.
channel.queue_declare(queue='balance')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='balance',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
队列持久化
当rabbitMQ意外宕机时,可能会有持久化保存队列的需求(队列中的消息不消失)。
producer:
# !/usr/bin/env python
import pika
credentials = pika.PlainCredentials('admin','123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.56.19',5672,'/',credentials))
channel = connection.channel()
# 声明queue
channel.queue_declare(queue='durable',durable=True)
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='durable',
body='Hello cheng!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent 'Hello cheng!'")
connection.close()
执行消费者代码cunsumer:
# _*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
credentials = pika.PlainCredentials('admin','123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.56.19',5672,'/',credentials))
channel = connection.channel()
# You may ask why we declare the queue again ‒ we have already declared it in our previous code.
# We could avoid that if we were sure that the queue already exists. For example if send.py program
# was run before. But we're not yet sure which program to run first. In such cases it's a good
# practice to repeat declaring the queue in both programs.
channel.queue_declare(queue='durable',durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback,
queue='durable',
#no_ack=True
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
订阅、路由和通配符模式,这三种模式都是用了Exchange交换机,消息没有直接发送到队列,而是发送到了交换机,经过队列绑定交换机到达队列。
一、订阅模式(Fanout Exchange):
一个生产者,多个消费者,每一个消费者都有自己的一个队列,生产者没有将消息直接发送到队列,而是发送到了交换机,每个队列绑定交换机,生产者发送的消息经过交换机,到达队列,实现一个消息被多个消费者获取的目的。需要注意的是,如果将消息发送到一个没有队列绑定的exchange上面,那么该消息将会丢失,这是因为在rabbitMQ中exchange不具备存储消息的能力,只有队列具备存储消息的能力。
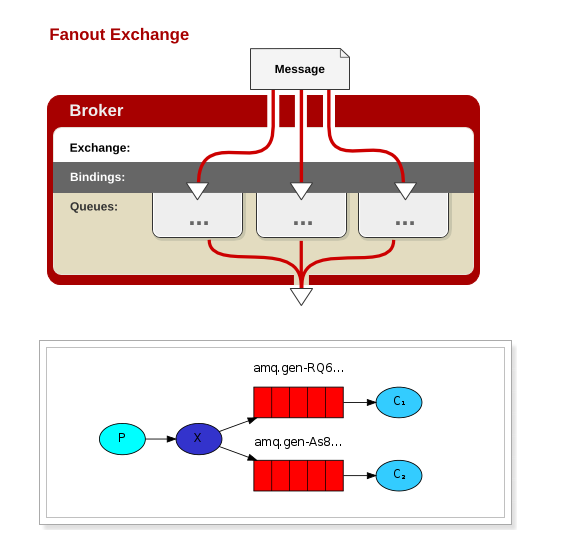
当producer发送消息到队列后,所有的consumer都会收到消息,需要注意的是,此模式下producer与concerned之间的关系类似与广播电台与收音机,如果广播后收音机没有接受到,那么消息就会丢失。
示例代码:
生产者producer:
import pika
import sys
credentials = pika.PlainCredentials('admin','123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.56.19',5672,'/',credentials))
channel = connection.channel()
channel.exchange_declare(exchange='Clogs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='Clogs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
接收者实现:
# _*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
credentials = pika.PlainCredentials('admin','123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.56.19',5672,'/',credentials))
channel = connection.channel()
channel.exchange_declare(exchange='Clogs',
type='fanout')
result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='Clogs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
